Helicone: The Next Evolution in OpenAI Monitoring and Optimization
How Helicone Fills the Monitoring and Optimization Gap in OpenAI’s Ecosystem so developers and businesses can make the most of their OpenAI usage.

OpenAI and the Future of AI
OpenAI’s suite of APIs has fundamentally altered the playing field for natural language processing and machine learning. Yet, while the focus has largely been on leveraging GPT-3, GPT-4, and other OpenAI models for application development, an equally critical area—monitoring and optimization—has not been given its due. Here we introduce how Helicone revolutionizes this space:
- Why Traditional Monitoring Falls Short
- Fully unlock the potential of our OpenAI usage
- Industry Leading Features purpose-built for LLM’s
- Trailblazing the Future of development with OpenAI
Why Traditional Monitoring Falls Short
Traditional monitoring solutions, while serviceable, were designed for linear and time-based data. They are not equipped to handle the complexities of OpenAI’s token-based system. As a result, they fail to provide the insights necessary to optimize OpenAI usage. Below is a table detailing some differences between traditional observability compared to LLM-observability:
| Legacy | Large-Language Models |
|---|---|
| Deterministic - app flow doesn’t change based on user behavior | Non Deterministic - Apps can go anywhere based on user prompt |
| Time Based - user interactions are logged with timestamps in a linear fashion | Session Based - user interactions revolve around solving problems, which can span hours or days |
| Security sits outside of the app, requiring additional controls at the app layer | Security built into the pipeline via Helicone’s proxy - can monitor, prevent, and limit users |
| Data structures and logs are consistent and predictable | LLM responses from different models and different providers are not unified |
| Logs are relatively small and represent single events | Context windows are massive and represent entire user interactions/history (100k context windows) |
Fully unlock the potential of our OpenAI usage
Helicone’s dashboard serves as your command center for driving operational efficiency in the use of OpenAI’s large language models. By consolidating key metrics like requests over time, associated costs, and latency into a single interface, Helicone offers an unparalleled, real-time overview that enables rapid, data-driven decisions. No more guesswork; just actionable insights that identify trends, isolate inefficiencies, and highlight opportunities for cost-saving and performance improvements.
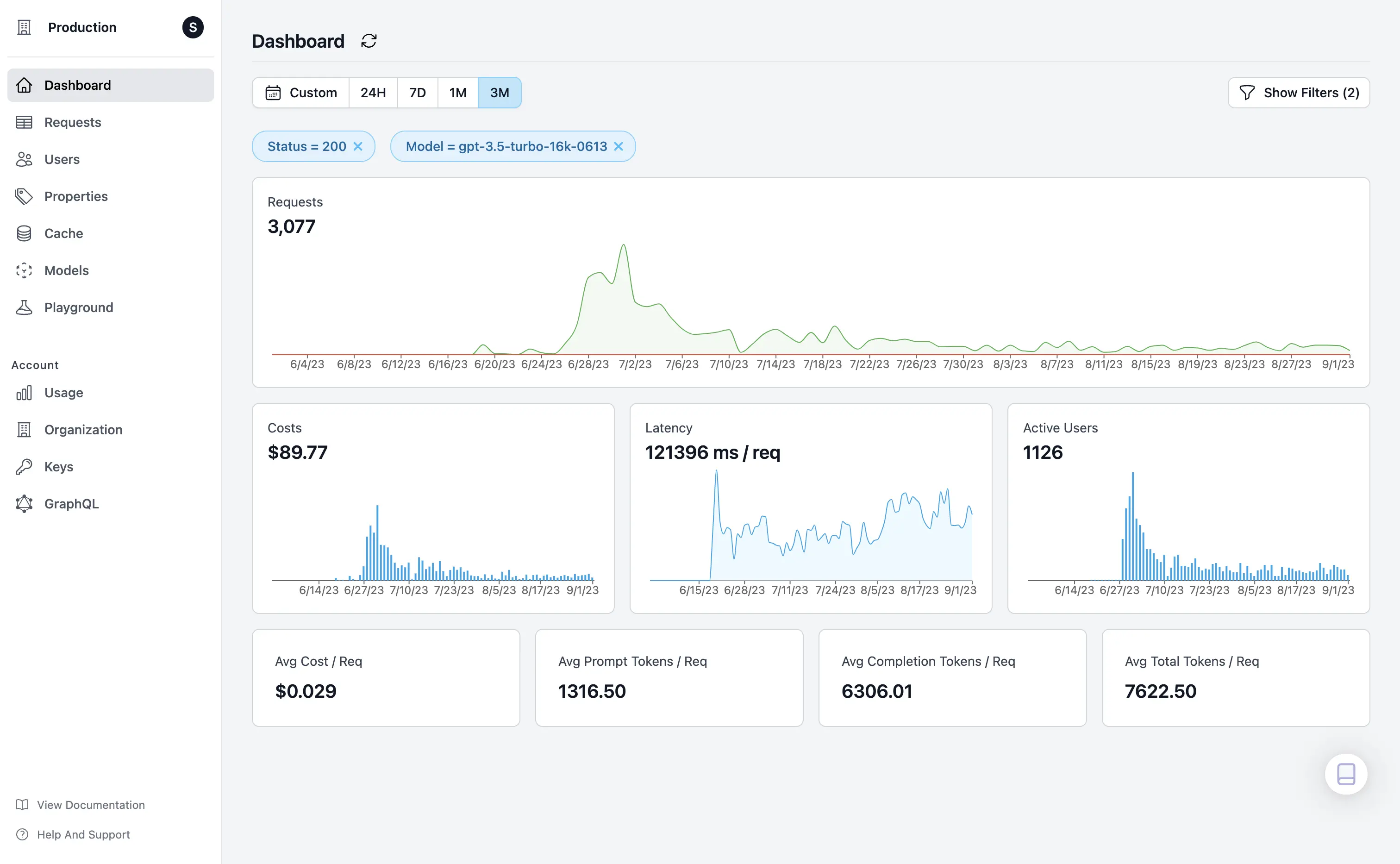 Users can monitor their OpenAI usage in real-time on the metrics they care about.
Users can monitor their OpenAI usage in real-time on the metrics they care about.
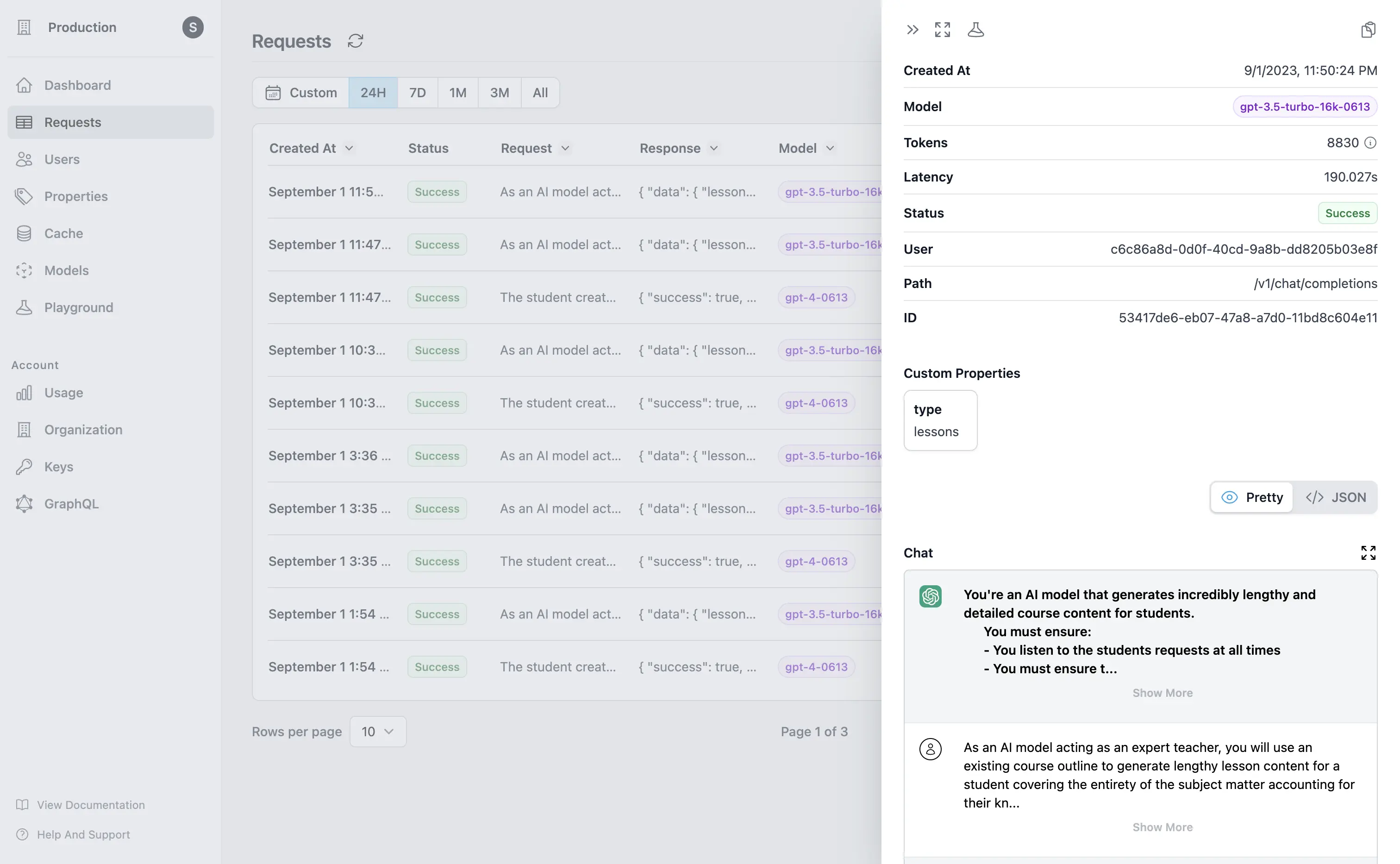 Users can view requests to view user behavior and usage patterns.
Users can view requests to view user behavior and usage patterns.
When you’re juggling a myriad of variables such as model selection, token consumption, and request latency, Helicone streamlines the complexity into digestible, easy-to-analyze data points. With features like active user tracking and model-specific metrics, you gain not only a snapshot of current usage but also predictive analytics that guide future optimization strategies. It’s not just about understanding where your resources are going; it’s about ensuring they are aligned most effectively with your business goals and performance expectations.
Industry Leading Features purpose-built for LLM’s
Navigating the complex landscape of OpenAI’s API is a technical challenge that requires more than rudimentary monitoring. Helicone offers an array of unique features designed with the precision and scalability that advanced users demand. From leveraging machine learning algorithms for adaptive rate-limiting to facilitating secure deployments through our Key Vault feature, Helicone goes beyond traditional monitoring to give you a genuine technical advantage.
-
Adaptive Rate Limiting. Traditional rate limiting is static and fails to adapt to your specific usage patterns. Helicone employs machine learning algorithms to adjust the rate limits dynamically based on your historical usage data.
-
Bucket Cache Feature. Instead of repetitively hitting the LLM-endpoint for similar requests, you can cache any ‘n’ amount of responses using our new bucket cache feature, saving on costs and improving latency.
-
Key Vault. Safely deploy LLMs across your organization, business, or educational institution with our secure Key Vault feature. This allows you to map your OpenAI keys to Helicone keys, ensuring internal deployments are as secure as they are efficient.
“It’s crazy to imagine a time before using Helicone. We had a rate limiting issue yesterday and found it immediately.” — Daksh Gupta, Founder, Onboard AI
Trailblazing the Future of development with OpenAI
Selecting Helicone is not merely a choice; it’s a decisive move toward operational excellence and insightful management of your OpenAI Large Language Models (LLMs). As the market evolves, so do we, continually innovating to bring you unparalleled features and capabilities. Helicone is committed to staying ahead of the curve as well as being open-source forever.
Unlike other platforms, Helicone is designed from the ground up to meet the unique challenges that come with deploying, managing, scaling, and optimizing LLMs. We take a holistic approach to resource management, ensuring not only top-notch monitoring but also secure, efficient, and intelligent usage of OpenAI models.
In conclusion, the choice of Helicone as your OpenAI management tool is more than an operational decision; it’s a commitment to staying ahead, embracing efficiency, and unlocking the full potential of your OpenAI resources. Check out our documentation or sign up for a 14 day free trial to get started with Helicone today.